Introducción.-
UML (Unified Modeling Language) es un lenguaje que permite modelar, construir y documentar los elementos que forman un sistema software orientado a objetos. Se ha convertido en el estándar de facto de la industria, debido a que ha sido concebido por los autores de los tres métodos más usados de orientación a objetos: Grady Booch, Ivar Jacobson y Jim Rumbaugh.
Estos autores fueron contratados por la empresa Rational Software Co. para crear una notación unificada en la que basar la construcción de sus herramientas CASE. En el proceso de creación de UML han participado, no obstante, otras empresas de gran peso en la industria como Microsoft, Hewlett-Packard, Oracle o IBM, así como grupos de analistas y desarrolladores.
CLASIFICACIÓN DE LOS MODELOS UML
Modelo estático (estructural)
Diagrama de clases
Diagrama de objetos
Diagrama de componentes
Diagrama de despliegue
Modelo dinámico (comportamiento)
Diagrama de actividades
Diagrama de casos de uso
Diagrama de estados
Diagrama de secuencia
Diagrama de colaboración
MODELO ESTÁTICO
DIAGRAMAS DE CLASES
un diagrama de clases es un tipo de diagrama estático que describe la estructura de un sistema mostrando sus clases, atributos y las relaciones entre ellos. Los diagramas de clases son utilizados durante el proceso de análisis y diseño de los sistemas informáticos.
Piense en las cosas que lo rodean, es probable que muchas de esas cosas tengan atributos(propiedades) y que realicen determinadas acciones. Podriamos imaginar cada una de esas acciones como conjunto de tareas.
Tambien se encontrara con que las cosas naturalmente se albergaran en categorias(automoviles, mobiliario, lavadoras). A tales categorias las llamaremos clases. Una clase es una categoria o grupo de cosas que tienen atributos y acciones similares, he aqui un ejemplo: cualquier cosa dentro de la clase lavadoras tiene atributos como son la marca, el modelo, el numero de serie y la capacidad. Entre las acciones de las cosas de esta clase se encuentran: agregar ropa, agregar detergente, activarse y sacar ropa.
DIAGRAMAS DE OBJETOS
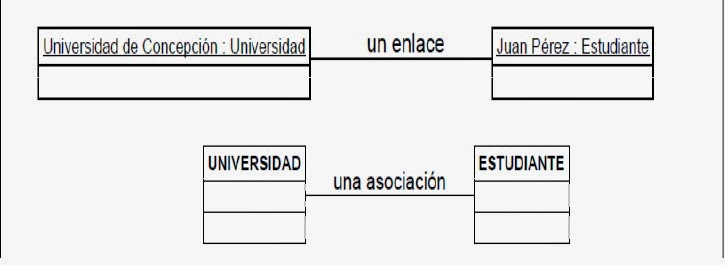
Los diagramas de objetos utilizan un subconjunto de los elementos de un diagrama de clase. Los diagramas de objetos no muestran la multiplicidad ni los roles, aunque su notación es similar a los diagramas de clase. Una diferencia con los diagramas de clase es que el compartimiento de arriba va en la forma, Nombre de objeto: Nombre de clase. Por ejemplo, Miguel: Persona. Alfredo Arcos: Persona
un objeto es una instancia de una clase(una entidad que tiene valores especificos de los atributos y acciones. Su lavadora, por ejemplo podria tener la marca goma, el modelo gomilla el nuemero de serie GL25647 Y una capacidad de 7 kg
Un Diagrama es una representación gráfica de una colección de elementos de modelado, a menudo dibujada como un grafo conexo de arcos (relaciones) y vértices (otros elementos del modelo). Un diagrama no es un elemento semántico, un diagrama muestra representaciones de elementos semánticos del modelo, pero su significado no se ve afectado por la forma en que son representados. Un diagrama está contenido dentro de un paquete.
La mayoría de los diagramas de UML y algunos símbolos complejos son grafos que contienen formas conectadas por rutas. La infomación está sobre todo en la topología, no en el tamaño o la colocación de los símbolos (hay algunas excepciones como el diagrma de secuencia con un eje métrico de tiempo). Hay tres clases importantes de relaciones visuales: conexión (generalmente de líneas a formas de dos dimensiones), contención (de símbolos por formas cerradas de dos dimensiones), y adhesión visual (un símbolo que está "cerca" de otro en un diagrama). Estas relaciones geométricas se reasignan a conexiones entre nodos en un gráfico en la forma analizada de la notación.
La notación de UML está pensada para ser dibujada en superficies bidimensionales. Algunas formas bidimensionales son proyecciones de formas tridimensionales tales como cubos, pero todavía se representan como íconos en una superficie bidimensional.
Hay cuatro clases de construcciones gráficas que se usan en la notación de UML: íconos, símbolos bidimensionales, rutas y cadenas.
Un ícono es una figura gráfica con un tamaño y forma fijos. No se amplía para contener a su contenido. Los iconos pueden aparecer dentro de símbolos de área, como terminadores en las rutas o como símbolos independientes que puedan o no conectar con las rutas.
Los símbolos de dos dimensiones tienen altura y anchura variables, y pueden ampliarse para permitir otras cosas tales como listas de cadenas o de otros símbolos. Muchos de ellos están divididos en compartimientos similares o de tipos diferentes. Las rutas se conectan con los símbolos, el arrastrar o suprimir uno de ellos afecta a su contenido y las rutas conectadas.
DIAGRAMAS DE COMPONENTES
Los componentes pertenecen al mundo físico, es decir, representan un bloque de construcción al modelar aspectos físicos de un sistema.
Los diagramas de componentes describen los elementos físicos del sistema y sus relaciones. Muestran las opciones de realización incluyendo código fuente, binario y ejecutable. Los componentes representan todos los tipos de elementos software que entran en la fabricación de aplicaciones informáticas. Pueden ser simples archivos, paquetes de Ada, bibliotecas cargadas dinámicamente, etc. Las relaciones de dependencia se utilizan en los diagramas de componentes para indicar que un componente utiliza los servicios ofrecidos por otro componente.
Un diagrama de componentes representa las dependencias entre componentes software, incluyendo componentes de código fuente, componentes del código binario, y componentes ejecutables. Un módulo de software se puede representar como componente. Algunos componentes existen en tiempo de compilación, algunos en tiempo de enlace y algunos en tiempo de ejecución, otros en varias de éstas.
Un componente de sólo compilación es aquel que es significativo únicamente en tiempo de compilación. Un componente ejecutable es un programa ejecutable.
Un diagrama de componentes tiene sólo una versión con descriptores, no tiene versión con instancias. Para mostrar las instancias de los componentes se debe usar un diagrama de despliegue.
Un diagrama de componentes muestra clasificadores de componentes, las clases definidas en ellos, y las relaciones entre ellas. Los clasificadores de componentes también se pueden anidar dentro de otros clasificadores de componentes para mostrar relaciones de definición.
Un diagrama que contiene clasificadores de componentes y de nodo se puede utilizar para mostrar las dependencias del compilador, que se representa como flechas con líneas discontinuas (dependencias) de un componente cliente a un componente proveedor del que depende. Los tipos de dependencias son específicos del lenguaje y se pueden representar como estereotipos de las dependencias.
El diagrama también puede usarse para mostrar interfaces y las dependencias de llamada entre componentes, usando flechas con líneas discontinuas desde los componentes a las interfaces de otros componentes.
El diagrama de componente hace parte de la vista física de un sistema, la cual modela la estructura de implementación de la aplicación por sí misma, su organización en componentes y su despliegue en nodos de ejecución. Esta vista proporciona la oportunidad de establecer correspondecias entre las clases y los componentes de implementación y nodos. La vista de implementación se representa con los diagramas de componentes.
DIAGRAMA DE DESPLIEGUE
Un diagrama de despliegue muestra las relaciones físicas entre los componentes hardware y software en el sistema final, es decir, la configuración de los elementos de procesamiento en tiempo de ejecución y los componentes software (procesos y objetos que se ejecutan en ellos).
Los Diagramas de Despliegue muestran la disposición física de los distintos nodos que componen un sistema y el reparto de los componentes sobre dichos nodos. La vista de despliegue representa la disposición de las instancias de componentes de ejecución en instacias de nodos conectados por enlaces de comunicación. Un nodo es un recurso de ejecución tal como un computador, un dispositivo o memoria. Los estereotipos permiten precisar la naturaleza del equipo:
• Dispositivos
• Procesadores
• Memoria
Los nodos se interconectan mediante soportes bidireccionales que pueden a su vez estereotiparse. Esta vista permite determinar las consecuencias de la distribución y la asignación de recursos. Las instancias de los nodos pueden contener instancias de ejecución, como instancias de componentes y objetos. El modelo puede mostrar dependencias entre las instancias y sus interfaces, y también modelar la migración de entidades entre nodos u otros contenedores.
Esta vista tiene una forma de descriptor y otra de instancia. La forma de instancia muestra la localización de las instancias de los componentes específicos en instancias específicas del nodo como parte de una configuración del sistema. La forma de descriptor muestra qué tipo de componentes pueden subsistir en qué tipos de nodos y qué tipo de nodos se pueden conectar, de forma similar a una diagrama de clases, esta forma es menos común que la primera.
MODELO DINÁMICO
DIAGRAMA DE CASO DE USO
Los diagramas de casos de uso organizan los comportamientos del sistema. Un diagrama de caso de uso representa un conjunto de casos de uso y actores (un tipo especial de clases) y sus relaciones.
Un caso de uso es la descripcion de las acciones de un sistema desde el punnto de vista del usuario. para los desarrolladores del sistema, esta es una herramienta valiosa, ya que es una tecnica de aciertos y errores para obtener los requerimientos del sistema desde el punto de vista del usuario. Esto es importante si la finalidad es crear un sistema que pueda ser utilizado por la gente en general (no solo por ezpertos en computacion)
Casos de Uso es una técnica para capturar información de cómo un sistema o negocio trabaja, o de cómo se desea que trabaje. No pertenece estrictamente al enfoque orientado a objeto, es una técnica para captura de requisitos.
•Los Casos de Uso (Ivar Jacobson) describen bajo la forma de acciones y reacciones el comportamiento de un sistema desde el p.d.v. del usuario.
• Permiten definir los límites del sistema y las relaciones entre el sistema y el entorno.
• Los Casos de Uso son descripciones de la funcionalidad del sistema independientes de la implementación.
• Comparación con respecto a los Diagramas de Flujo de Datos del Enfoque Estructurado.
• Los Casos de Uso cubren la carencia existente en métodos previos (OMT, Booch) en cuanto a la determinación de requisitos.
• Los Casos de Uso particionan el conjunto de necesidades atendiendo a la categoría de usuarios que participan en el mismo.
• Están basados en el lenguaje natural, es decir, es accesible por los usuarios.
Actores
• Principales: personas que usan el sistema.
• Secundarios: personas que mantienen o administran el sistema.
• Material externo: dispositivos materiales imprescindibles que forman parte del ámbito de la aplicación y deben ser utilizados.
• Otros sistemas: sistemas con los que el sistema interactúa.
La misma persona física puede interpretar varios papeles como actores distintos, el nombre del actor describe el papel desempeñado.
Los Casos de Uso se determinan observando y precisando, actor por actor, las secuencias de interacción, los escenarios, desde el punto de vista del usuario. Los casos de uso intervienen durante todo el ciclo de vida. El proceso de desarrollo estará dirigido por los casos de uso. Un escenario es una instancia de un caso de uso.
DIAGRAMAS DE ESTADOS
Un Diagrama de Estados muestra la secuencia de estados por los que pasa un caso de uso o un
objeto a lo largo de su vida, indicando qué eventos hacen que se pase de un estado a otro y
cuáles son las respuestas y acciones que genera.
en cualquier momento un objeto se encuentra en un estado en particular. Una persona puede ser nacida, infante, adolescente o adulto. Un elevador se movera hacia arriba, estara en estado de reposo o se movera hacia abajo. Una lavadora podra estar en la fase de remojo, lavado, enjuague, centrifugado o apagada
Un Diagrama es una representación gráfica de una colección de elementos de modelado, a menudo dibujada como un grafo conexo de arcos (relaciones) y vértices (otros elementos del modelo). Un diagrama no es un elemento semántico, un diagrama muestra representaciones de elementos semánticos del modelo, pero su significado no se ve afectado por la forma en que son representados. Un diagrama está contenido dentro de un paquete.
La mayoría de los diagramas de UML y algunos símbolos complejos son grafos que contienen formas conectadas por rutas. La infomación está sobre todo en la topología, no en el tamaño o la colocación de los símbolos (hay algunas excepciones como el diagrma de secuencia con un eje métrico de tiempo). Hay tres clases importantes de relaciones visuales: conexión (generalmente de líneas a formas de dos dimensiones), contención (de símbolos por formas cerradas de dos dimensiones), y adhesión visual (un símbolo que está "cerca" de otro en un diagrama). Estas relaciones geométricas se reasignan a conexiones entre nodos en un gráfico en la forma analizada de la notación.
La notación de UML está pensada para ser dibujada en superficies bidimensionales. Algunas formas bidimensionales son proyecciones de formas tridimensionales tales como cubos, pero todavía se representan como íconos en una superficie bidimensional.
Hay cuatro clases de construcciones gráficas que se usan en la notación de UML: íconos, símbolos bidimensionales, rutas y cadenas.
Un ícono es una figura gráfica con un tamaño y forma fijos. No se amplía para contener a su contenido. Los iconos pueden aparecer dentro de símbolos de área, como terminadores en las rutas o como símbolos independientes que puedan o no conectar con las rutas.
Los símbolos de dos dimensiones tienen altura y anchura variables, y pueden ampliarse para permitir otras cosas tales como listas de cadenas o de otros símbolos. Muchos de ellos están divididos en compartimientos similares o de tipos diferentes. Las rutas se conectan con los símbolos, el arrastrar o suprimir uno de ellos afecta a su contenido y las rutas conectadas.
DIAGRAMAS DE ACTIVIDADES
Un diagrama de actividades representa los flujos de trabajo paso a paso de negocio y operacionales de los componentes en un sistema.
Las actividades que ocurren dentro de un caso de uso o dentro del comportamiento de un objeto se dan normalmente en secuencia
El Diagrama de Actividad es un diagrama de flujo del proceso multi-propósito que se usa para modelar el comportamiento del sistema. Los diagramas de actividad se pueden usar para modelar un Caso de Uso, o una clase, o un método complicado.
Un diagrama de actividad es parecido a un diagrama de flujo; la diferencia clave es que los diagramas de actividad pueden mostrar procesado paralelo (parallel processing). Esto es importante cuando se usan diagramas de actividad para modelar procesos 'bussiness' algunos de los cuales pueden actuar en paralelo, y para modelar varios hilos en los programas concurrentes.
DIAGRAMA DE SECUENCIA
El diagrama de secuencia es uno de los diagramas más efectivos para modelar interacción entre objetos en un sistema. Un diagrama de secuencia muestra la interacción de un conjunto de objetos en una aplicación a través del tiempo y se modela para cada método de la clase.
Los diagramas de clases y los de objeto representan informacion estatica. No obstante en un sistema funcional los objetos interactuan entre si, y tales interacciones suceden con el tiempo, el diagrama de secuencia muestra la mecanica de la interaccion con base en tiempos
Los 4 pasos a seguir:
A continuación se dará una muy breve descripción de los 4 pasos que se deben de seguir para dibujar correctamente diagramas de secuencia de ICONIX:
-Paso 1: Copia el texto de la especificación de tu caso de uso y pégalo en la parte superior de tu diagrama de secuencia. Con esto siempre se tendrá en cuenta que es lo que debe de hacer el diagrama de secuencia.
-Paso 2: Cada uno de los objetos entidad de tu diagrama de robustez es una instancia de la clase que debe de ser agregada a tu diagrama de secuencias ya que representa tu modelo estático. Hay que ser muy meticuloso con este paso, ya que representa el ultimo de tu modelo estático antes de codificar.
-Paso 3: Agrega las interfaces del diagrama de robustez. Con esto ya tenemos el diagrama de secuencias construido. Ahora, el cuarto paso es para decidir cuales métodos irían en cuales clases, lo cual es la esencia del modelo de iteraciones.
-Paso 4: Pon los métodos en las clases, lo cual significa convertir los controles uno por uno de tu diagrama de robustez en métodos y mensajes. Verifica que para cada control dibujado le pertenecen los mensajes correctos dentro del diagrama de secuencias.
DIAGRAMA DE COLABORACIÓN
Los diagramas de colaboración muestran explícitamente las relaciones de los roles. Por otra parte, un diagrama de colaboración no muestra el tiempo como una dimensión aparte, por lo que resulta necesario etiquetar con números de secuencia tanto la secuencia de mensajes como los hilos concurrentes.
Los elementos de un sistema trabajan en conjunto para cumplir los objetivos del sistema, y un lenguaje de modelado debera contar con una forma de representar esto, el diagrama de colaboracion esta diseñado con en este fin
Es una descripción de una colección de objetos que interactúan para implementar un cierto comportamiento dentro de un contexto. Describe una sociedad de objetos cooperantes unidos para realizar un cierto propósito. Una colaboración contiene ranuras que son rellenadas por los objetos y enlaces en tiempo de ejecución. Una ranura de colaboración se llama Rol porque describe el propósito de un objeto o un enlace dentro de la colaboración.
Un rol clasificador representa una descripción de los objetos que pueden participar en una ejecución de la colaboración, un rol de asociación representa una descripción de los enlaces que pueden participar en una ejecución de colaboración. Un rol de clasificador es una asociación que está limitada por tomar parte en la colaboración. Las relaciones entre roles de clasificador y asociación dentro de una colaboración sólo tienen sentido en ese contexto. En general fuera de ese contexto no se aplican las mismas relaciones.
Una Colaboración tiene un aspecto estructural y un aspecto de comportamiento. El aspecto estrucutral es similar a una vista estática: contiene un conjunto de roles y relaciones que definen el contexto para su comprtamiento. El comportamiento es el conjunto de mensajes intercambiados por los objetos ligados a los roles. Tal conjunto de mensajes en una colaboración se llama Interacción. Una colaboración puede incluir una o más interacciones.